Attempts to measure diversity of CodeLM generations
Introduction
Code language models are used in the context of code completion and chat interfaces day in, day out by software developers to write and contribute to code bases. Programming languages are formal in nature, with a fixed, strict set of rules. This pushes us to study quantifying and measuring how diverse the generations produced by these models are in various settings — and more importantly, it makes us wonder what diversity even is in the context of code. This post aims to explore and understand the diversity of code-LM generations, and to surface various shortcomings in measuring it in controlled settings. Throughout, I use the HumanEval benchmark, which evaluates function-level code completion for functional correctness — measuring accuracy by passing the given test cases within the first k out of n samples.
Semantic and syntactic diversity
The general notion of syntax and semantics in programming languages is slightly different from that of natural language. Syntax refers to the structure of the code — the rules that govern how it is written. Semantics refers to the intention of a given piece of code. Here is a small example of semantically similar code snippets that can be expressed with varied syntax while remaining functionally equivalent.
The formal structure of code allows for a wide range of syntactic variations. Diversity of a code LM in the context of code can thus be formally defined as functionally equivalent, semantically similar generations. While the notion of diversity might be very small in tiny snippets, it grows with more abstract, real-world software.
HumanEval benchmark
The HumanEval benchmark, introduced in Codex, is a popular benchmark widely used to measure the performance of code LMs. It evaluates function-level code completion for functional correctness, measuring accuracy by passing the given test cases within the first k out of n samples.
Diversity metrics
A coherent way to quantify diversity is to look at the latent representations of different completions given a prompt. This can be done by using a good embedding model and performing some cluster analysis over the latent representations of the completions. While this method has its shortcomings, it is a good starting point. The ideal end goal would be to measure how semantically diverse and functionally equivalent the generations are, given a single prompt.
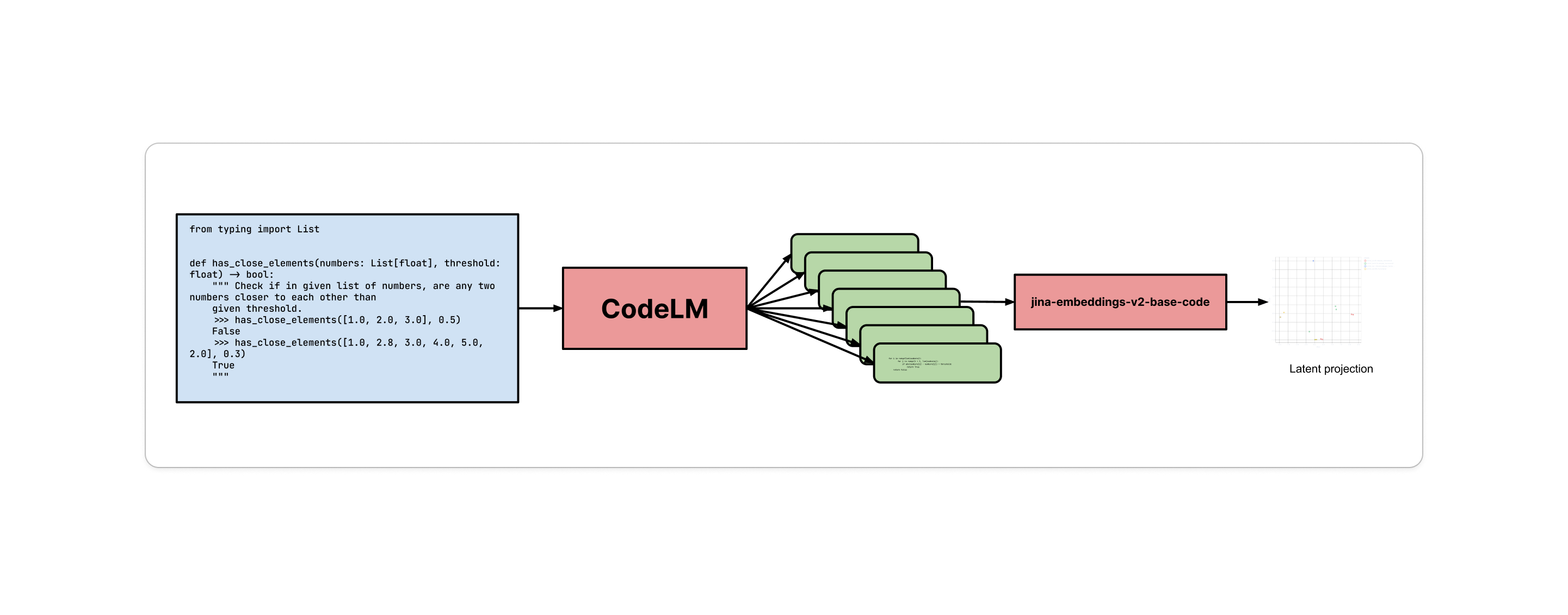
Limitations of code embedding models in modeling semantics
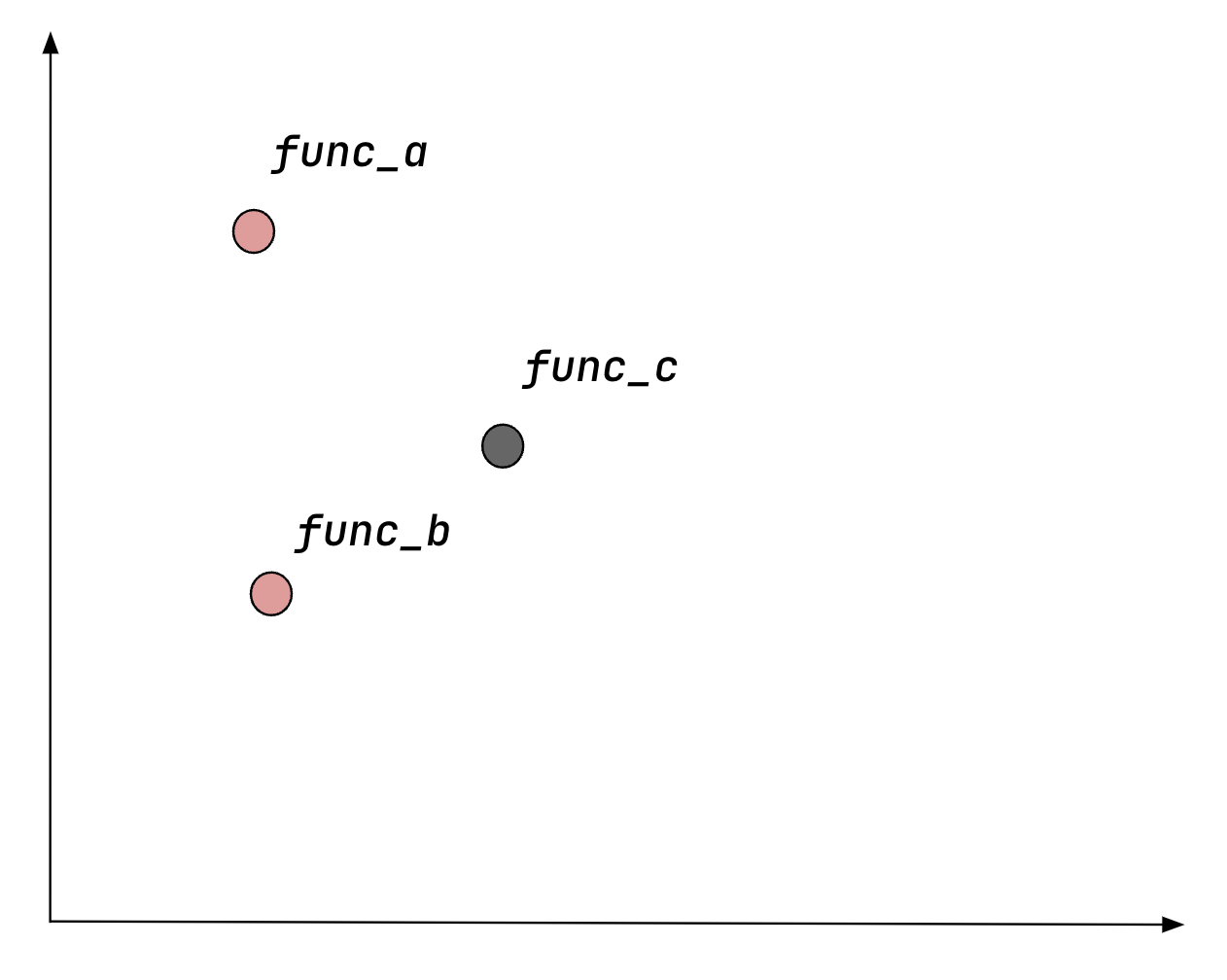
Unlike natural language — where the semantics of a sentence can be understood by looking at the words and their order — the semantics of a code snippet is not just its syntactic elements and their order. It also depends on the structure of the code, the state used, the functions called, the libraries imported, and so on. This makes it difficult to model the semantics of a code snippet using just lexical tokens and their order, and it makes the model heavily biased toward syntax rather than actual semantic similarity. For instance, consider three functions:
def func_a(l):
return max(l)
def func_b(l):
max_element = l[0]
for i in l:
if i > max_element:
max_element = i
return max_element
def func_c(l):
max_element = l[0]
return max_elementfunc_a and func_b are semantically similar — both find the maximum element of a list. But func_c is actually bugged, even though its variable naming nudges the model to map its latents close to the others. The true functional equivalent of func_a is func_b, yet the model tends to be severely biased toward syntax rather than the actual semantics of the code.
Observations
For a controlled experiment, we take the following models and run the analysis on them:
- deepseek-coder-1.3B
- deepseek-coder-6.7B
- deepseek-coder-33B
We use n_samples = 10 and temperature = 0.2 to maintain consistency across scale. The choice assumes the models are trained on a similar — if not the same — amount of data, and are base models with no high-quality fine-tuning data encapsulated in the training run, since the dynamics of generation quality may differ after the fine-tuning phase. We use average pairwise distance and squared-sum error as the metrics to measure the closeness and tightness of the latent representations of the generations.
A first glance at the results suggests that the smaller models produce more diverse generations than the larger ones — but the reality is quite different.
Scenario 1 — an easy-to-solve problem
These are problems mostly solved by all three models within a pass@100 / pass@10 cap. Careful exploration of the generations reveals how the 1.3B model specifically produces code with different newline and whitespace counts. An easy-to-solve example is shown below; in the 1.3B case the generated code was not functionally correct in 6 out of 10 cases.
#1.3B--example-1
from typing import List
def has_close_elements(numbers: List[float],threshold: float) -> bool:
numbers.sort()
for i in range(1, len(numbers)):
if numbers[i] - numbers[i-1] < threshold:
return True
return False
#1.3B--example-2
def has_close_elements(numbers: List[float],threshold: float) -> bool:
numbers.sort()
for i in range(1 , len(numbers)) :
if numbers[i] - numbers[i-1] < threshold :
return True
return FalseFor the same example, the 6.7B and 33B models consistently generate the exact same code snippet for easy problems.
from typing import List
def has_close_elements(numbers: List[float], threshold: float) -> bool:
for i in range(len(numbers)):
for j in range(i + 1, len(numbers)):
if abs(numbers[i] - numbers[j]) < threshold:
return True
return FalseExact AST match & performance
| Model | AST exact match | pass@1 |
|---|---|---|
| Deepseek-coder-1.3B | 60.7% | 30.2% |
| Deepseek-coder-6.7B | 45.6% | 45.0% |
| Deepseek-coder-33B | 31.7% | 53.6% |
This table measures exact AST matches among generations that are parseable, valid code. The pass@1 metric is the percentage of generations that pass the test cases on the first generation. The results are quite interesting: the 1.3B model has the highest exact AST match among its generations. This is in line with the hypothesis that diversity is directly correlated with performance — more diverse generations are more likely to contain the solution. Reiterating: diversity is defined as functionally equivalent, semantically similar generations.
You can explore the solutions generated by these models here.
Conclusion and future directions
A proper measure of diversity — defined as functionally equivalent, semantically similar generations — can act as a secondary metric to lean on, in addition to a model's correctness in generating a solution for a given problem. When a model produces high-quality, diverse generations, it increases the probability that the output search space contains the solution within a given turn. Current methods for measuring diversity in code are heavily biased toward syntax rather than the actual semantics that represent useful diversity. The future direction is to explore how to measure the actual diversity of code-LM generations.
Cite
@inproceedings{reshint-code-lm-div,
title = "How diverse are the generations of CodeLMs?",
author = "Reshinth Adithyan",
month = april,
year = "2024"}